Linking it Together
There comes a point where every aspiring programmer must take their data structures class. That time is upon me, so I decided to give myself a head start. Today, I’ll be discussing what a Linked List is, including inline implementations for convenience.
As the name would suggest, Linked Lists are structures comprised of a sequence of nodes that hold some set of data. It’s a simple and elegant model that can be used as the basis for implementations of stacks, queues, and hashmaps.
But the question becomes, why use a Linked List instead of something like an array?
Firstly, arrays contain a fixed size or length, which detail how much data it will hold. Upon initialization, memory is allocated in regards to this specific size. However, Linked Lists are a dynamic data structure, allowing it to scale its size and allocate memory during runtime.
Due to arrays’ fixed size, it becomes difficult to add data if the array is already full. To do so would require initializing a completely new array with a larger size, then copying over the values. However, Linked Lists allow you to dynamically scale the list, regardless of the desired size, making adding data a lot more convenient.
Say we wanted to add some data at a specific position within the list, like the middle. This can be quite an intensive task for arrays; they have to shift all the data to the right of the position, changing each element’s position. If you have a large list, this becomes quite inefficient. However, the nodes in Linked Lists contain pointers to their neighboring nodes, allowing new data to be inserted just by updating the pointers.
Now that we’ve discussed the benefits of Linked Lists, what different types are there?
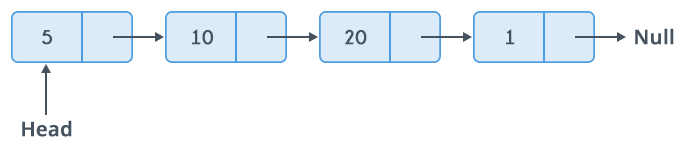
As you can see in the diagram above, a singly linked list features a sequence of nodes that contain some set of data, along with a pointer or reference to the very next item. The last node will remain “null”, as if contains no data to store in memory.
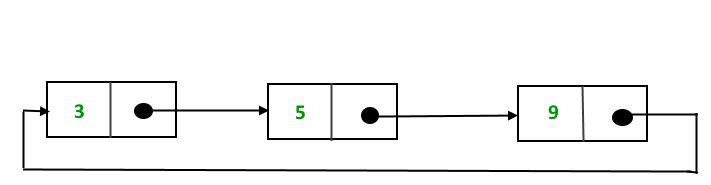
A circular linked list follows a similar approach, however there's one major addition. Instead of “null”, the last node will reference the first node of the list. The diagram above shows an example of constructing this pointer.

A doubly circular linked list will follow the same structure of a circular linked list, however there is a single addition to how the nodes function. With both circular and singly linked lists, we saw that the nodes only contained a reference to their next node. However in a doubly linked list, the nodes contain a reference to the node before them as well. Typically, this makes traversing the data a lot more efficient when dealing with larger lists. The diagram above demonstrates the relationship between the nodes in this particular structure.
Now that we have the basic concepts down, how would we implement these?
As you can see above, we define the architecture for a basic node. We use the identifier “data” to denote the content that the Node would hold, and “next” which will contain the pointer to the next node in the list. In addition, we define both the constructor and an initialization list that construct the node upon initialization.
Similarly, this example demonstrates how to construct a node in a doubly linked list. However, we can see there is the added “prev” identifier, that would contain the pointer to the previous node.
We briefly discussed the major differences in adding/removing data between both a linked list and array, but now let’s take a closer look.
 When inserting data into the list, we are spared the CPU intensive task of shifting the whole list and their respective positions, with arrays. Instead whenever a new node is created, it’s memory address is set to the “next” property of the previous node, and it sets its own “next” property to the node after it. In the diagram above, the new node is being placed in the middle of the list by assigning the pointers between Node B and Node C. This allows the new Node E to be added by only changing the data of Node B (the previous node). Naturally, this is quite efficient, but how would we implement this?
When inserting data into the list, we are spared the CPU intensive task of shifting the whole list and their respective positions, with arrays. Instead whenever a new node is created, it’s memory address is set to the “next” property of the previous node, and it sets its own “next” property to the node after it. In the diagram above, the new node is being placed in the middle of the list by assigning the pointers between Node B and Node C. This allows the new Node E to be added by only changing the data of Node B (the previous node). Naturally, this is quite efficient, but how would we implement this?
This may look overwhelming but fear not, it is actually quite simple. Firstly, there are two things to check when creating data. We must check whether or not the list already has a head or first node, if so we can simply tack on the data. However, if there is no data present in the list, we have to make sure the new node is created as the initial head node. Line 9 is where the new node is created, based on the structure defined earlier in this article. Line 11 is the first check, determining whether there is already a head node or not. In the case there isn’t, lines 14-15 create and set the head node. Provided there is already a head node, we must acquire the last node in the list, so that we can change its “next” property to the new node. Lines 21-26 iterate through the list to find that last node (tmp). Once it’s been acquired, we simply set the last node’s “next” property to the new node, as shown on line 28. Line 29 is the difference between a circular and singly linked list, it sets the new node’s “next” property to the head node, instead of NULL.

As the name would suggest, Linked Lists are structures comprised of a sequence of nodes that hold some set of data. It’s a simple and elegant model that can be used as the basis for implementations of stacks, queues, and hashmaps.
But the question becomes, why use a Linked List instead of something like an array?
Firstly, arrays contain a fixed size or length, which detail how much data it will hold. Upon initialization, memory is allocated in regards to this specific size. However, Linked Lists are a dynamic data structure, allowing it to scale its size and allocate memory during runtime.
Due to arrays’ fixed size, it becomes difficult to add data if the array is already full. To do so would require initializing a completely new array with a larger size, then copying over the values. However, Linked Lists allow you to dynamically scale the list, regardless of the desired size, making adding data a lot more convenient.
Say we wanted to add some data at a specific position within the list, like the middle. This can be quite an intensive task for arrays; they have to shift all the data to the right of the position, changing each element’s position. If you have a large list, this becomes quite inefficient. However, the nodes in Linked Lists contain pointers to their neighboring nodes, allowing new data to be inserted just by updating the pointers.
Now that we’ve discussed the benefits of Linked Lists, what different types are there?
Types
Depending on the use cases, there are various types of Linked Lists that can be implemented. These variations include a singly, circular, and doubly circular linked lists. Generally, both circular and doubly circular make traversing the data of the list a lot easier, however I will touch base on that later on.Singly Linked List
As you can see in the diagram above, a singly linked list features a sequence of nodes that contain some set of data, along with a pointer or reference to the very next item. The last node will remain “null”, as if contains no data to store in memory.
Circular Singly Linked List
A circular linked list follows a similar approach, however there's one major addition. Instead of “null”, the last node will reference the first node of the list. The diagram above shows an example of constructing this pointer.
Doubly Circular Linked List
A doubly circular linked list will follow the same structure of a circular linked list, however there is a single addition to how the nodes function. With both circular and singly linked lists, we saw that the nodes only contained a reference to their next node. However in a doubly linked list, the nodes contain a reference to the node before them as well. Typically, this makes traversing the data a lot more efficient when dealing with larger lists. The diagram above demonstrates the relationship between the nodes in this particular structure.
Now that we have the basic concepts down, how would we implement these?
Node Structure
As you can see above, we define the architecture for a basic node. We use the identifier “data” to denote the content that the Node would hold, and “next” which will contain the pointer to the next node in the list. In addition, we define both the constructor and an initialization list that construct the node upon initialization.
Similarly, this example demonstrates how to construct a node in a doubly linked list. However, we can see there is the added “prev” identifier, that would contain the pointer to the previous node.
We briefly discussed the major differences in adding/removing data between both a linked list and array, but now let’s take a closer look.
Adding Data
This may look overwhelming but fear not, it is actually quite simple. Firstly, there are two things to check when creating data. We must check whether or not the list already has a head or first node, if so we can simply tack on the data. However, if there is no data present in the list, we have to make sure the new node is created as the initial head node. Line 9 is where the new node is created, based on the structure defined earlier in this article. Line 11 is the first check, determining whether there is already a head node or not. In the case there isn’t, lines 14-15 create and set the head node. Provided there is already a head node, we must acquire the last node in the list, so that we can change its “next” property to the new node. Lines 21-26 iterate through the list to find that last node (tmp). Once it’s been acquired, we simply set the last node’s “next” property to the new node, as shown on line 28. Line 29 is the difference between a circular and singly linked list, it sets the new node’s “next” property to the head node, instead of NULL.
Removing Data
Removing data from the list becomes as simple and efficient as adding data, an important benefit over normal arrays. As we saw when inserting a node, we had to modify the previous node’s “next” property to point to the new node. Respectively when removing a node, we find the node behind it and reassign it’s “next” property to the address of the following node. The diagram shows this, as (previous) Node B’s “next” property is reassigned to Node D, which is in front of the targeted Node C. Let’s look at an example of this below.
Firstly, there are a couple things to check when removing data. We need to verify there is data within the list, we accomplish this by checking that the head node exists (lines 9-13). Then we iterate through the list to find the targeted data (lines 18-27). As we initially define tmp as the head node, we need to make sure the target was found and reassigned to tmp (lines 29-33). When removing the data, we need to take extra precaution if the node happens to be the head node. If it is (line 35), we obtain the first node’s “next” property to find the following node, which we assign as the new head after destroying the initial head node (lines 37-46). However, if the targeted data is not contained in the head, we are able to simply reassign the pointers and delete the node (lines 50-53).
That’s the Wrap!
We explored what a Linked List, the various types that can be used, and their primary functions. Learning about where they may be used and how they compare to something like Arrays, helps us create a more organized environment for implementations. In addition, we learned about the basic functions for dynamically adding/removing data from the list. Regardless of your experience, I hope this provides some insight into the Linked List model and how it may be implemented or used to your benefit.
The code samples listed above are taken from my full implementation of the three types of Linked Lists, you may find a link to the project here.
Comments
Post a Comment